
許多開發者初次接觸 AI Agent,會被 ReAct (Reasoning and Acting) 框架的簡潔與強大所吸引,並迅速用幾十行程式碼實現一個能與工具互動的簡單 Agent,甚至不需要使用到任何套件。
這很棒,卻也容易造成一種錯覺:既然能動,就離上線不遠了。真正在複雜客戶端場景(斷線重連、頁面重整、多工具協作、人工審批、長任務)提供穩定、可維運的體驗,往往要靠完整的 Agent Framework 來補齊工程面的縫隙。ReAct 是提示與互動的模式,而一個好的 Framework 才是把它變成產品的關鍵。
短短幾行程式碼,就能實現一個「Thought -> Action -> Observation」的閉環,讓模型看起來像是在推理、決策,甚至一步步探索問題解法。這種直觀的迴圈往往能在黑板上、在簡報中、甚至在 hackathon 裡迅速展現效果,給人一種「智慧真的在這裡誕生」的感覺。
它的魅力來自於:
Thought -> Action -> Observation,流程清楚、直觀易懂。然而,這種看似堅固的迴圈,其實更像漂浮在水面上的冰山頂端。當場景變得複雜,隱藏在水面下的結構性脆弱就會暴露出來:
它的脆弱之處在於:
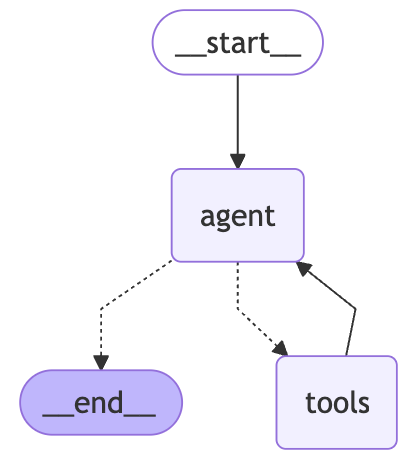
一個能跑起來的 ReAct 迴圈,就像搭好的雛形引擎;它能啟動,但遠遠不足以驅動真實世界的任務。要讓 Agent 走進產品環境並承受長時間運行、斷線重連、多角色協作等挑戰,必須有幾根「支柱」撐住它。
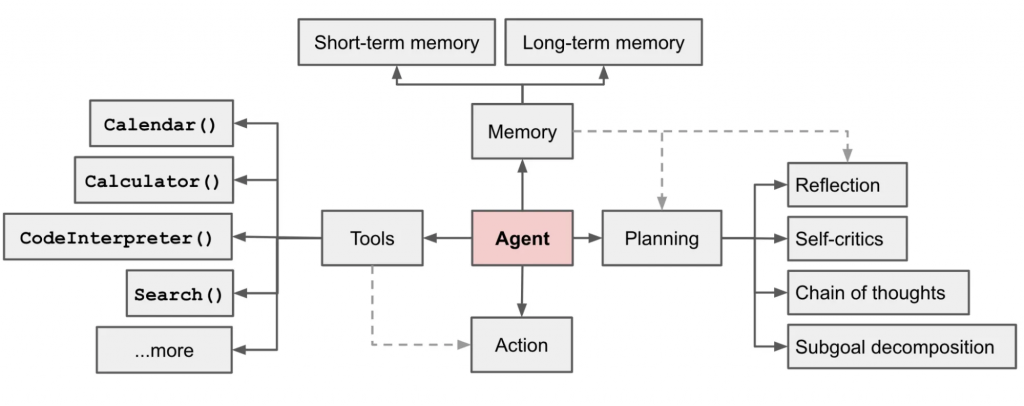
這些支柱分別解決三個現實問題:如何保持對話與任務的連貫性(記憶體管理)、如何確保遇到中斷仍能繼續(持久性與狀態管理)、以及如何處理非線性的決策與人機協作(工作流設計)。沒有這些支柱,Agent 就只能停留在玩具階段;有了它們,才有機會演變成能真正落地的應用。
🚫 沒有記憶的 LLM
使用者:嗨,我叫 Mike Hsu。
LLM:嗨,很高興認識你!
使用者:我剛才說我叫什麼名字?
LLM:抱歉,我不確定,你還沒告訴過我。
-----
✅ 有記憶的 LLM(具備短期對話記憶)
使用者:嗨,我叫 Mike Hsu。
LLM:嗨,Mike Hsu,很高興認識你!
使用者:我剛才說我叫什麼名字?
LLM:你剛才說你叫 Mike Hsu。
沒有記憶的 Agent,就像金魚般每 7 秒認識一次你;它也許能完成一兩步互動,但很快就會在冗長任務與跨會話需求前現出原形。真正的「智慧」,來自於能把當下的上下文抓牢(短期記憶),並把跨時間的偏好與知識沉澱下來(長期記憶)。兩者相互配合:前者保證對話不斷線,後者讓互動越用越懂你。
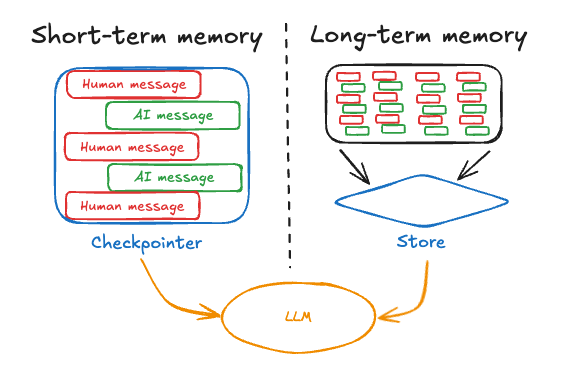
短期記憶(Short-term Memory)
短期記憶主要承擔「當前脈絡」的維護。例如在一段對話或任務流程中,Agent 需要記住使用者剛剛的訊息、工具呼叫的結果、暫存的變數。這讓互動變得自然連貫,而不是每次都要從頭解釋。短期記憶通常以對話歷史、上下文緩衝或臨時狀態儲存來實現。
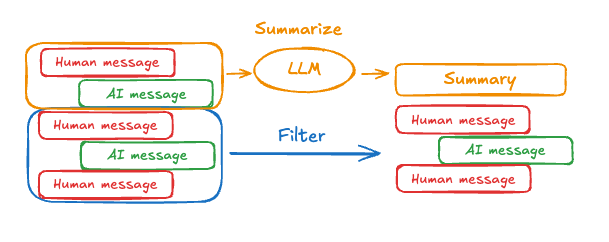
在 Agent 具備短期記憶後,一個常見挑戰是長對話很快就會超出語言模型的上下文視窗。為了避免這種情況,系統通常需要有一套「記憶管理」機制。最基本的做法是修剪訊息,也就是在送入模型前刪除過舊或不重要的對話內容。
進一步的方式是透過摘要,將早期的歷史濃縮成簡短的敘述,保留核心語意而非逐字回放。除此之外,也能利用檢查點的方式,把對話歷史儲存下來,必要時再擷取,甚至可以設計更進階的自訂策略,例如依訊息的角色、主題或重要性來篩選。這些方法讓代理能在對話過程中持續「記得你剛剛說過什麼」,同時又不會因為訊息過多而壓垮模型的上下文限制。
長期記憶(Long-term Memory)
如果短期記憶讓代理能在單一對話中保持流暢,那麼長期記憶就是讓代理「跨越時間」的基礎。它的目的在於實現個人化與知識沉澱,讓系統不僅能記得你在這一輪說了什麼,也能在不同的 session 中延續對你的理解,逐步形成「這就是你」的形象。
長期記憶的挑戰在於,它不像短期記憶有一個簡單的上下文視窗上限,而是涉及「該記住什麼」、「怎麼更新」、「何時取用」等更複雜的問題。人類的記憶可分為語義(事實)、情景(經驗)、程序(規則),同樣的分類也能套用在 AI 代理身上:它可以記住使用者的偏好與基本資料(事實記憶)、過往互動的脈絡(情景記憶),甚至在任務執行中累積規則或模式(程序記憶)。
在技術上,常見的做法包括:
而另一個核心問題是「什麼時候更新記憶」。有些系統會選擇在互動中立即更新(熱路徑),例如在回覆使用者前,就把新事實寫進記憶體;也有些則會以背景任務的方式定期同步與整理,避免即時影響效能。兩者各有取捨:即時更新能保持高度個人化,但可能增加延遲;背景更新則更有效率,但需要設計良好的觸發條件與一致性策略。
最後,長期記憶的價值還在於提供一個統一介面,能輕鬆掛接不同的儲存後端(像是 Redis、Postgres、向量資料庫等),並附帶命名空間、TTL(存活時間)或清理策略,確保資料不會無限制膨脹,也能兼顧隱私與合規。
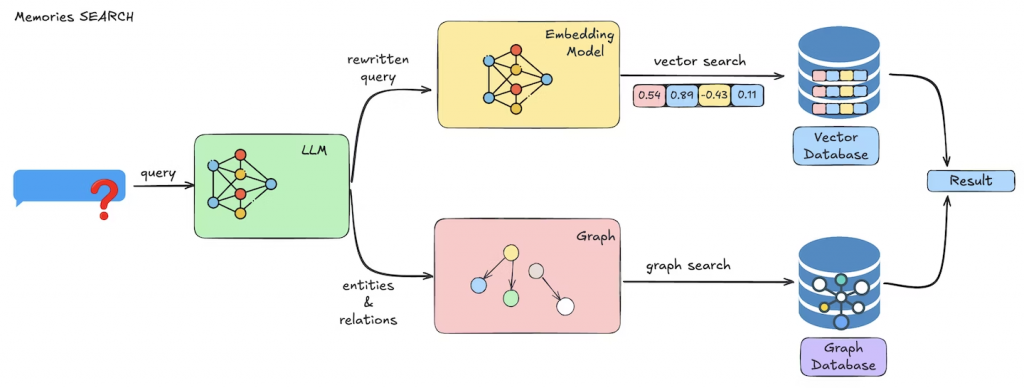
長期記憶的挑戰在於既要跨越多個 Session 保存資訊,又要確保檢索效率與語義相關性。
Mem0 提供了一個相對清晰的實作範式:
這樣的設計讓代理不只是「看見當下的訊息」,還能在對話之間保有連續的自我,逐步累積對使用者的認識與任務經驗。
使用者真正信任的,不是「每次都從頭再來」的巧合成功,而是無論發生什麼都能完成任務的確定性。手機切 App、網路忽明忽滅、伺服器重啟……若你的 Agent 提供良好的一致性,那正是從玩具級瞬間跨進產品級的分水嶺。
核心情境
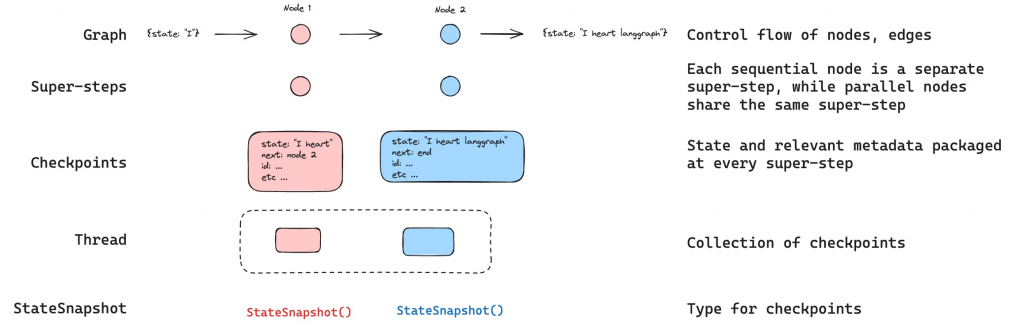
框架解法:檢查點(Checkpoints)+時間旅行(Time Travel)
狀態(State) 序列化到儲存層(SQLite / Redis / Postgres)。狀態包含中間步驟的輸入輸出、變數與當前節點位置。在持久化工作流中,系統並不會「從程式碼停下來的那一行繼續」,而是會回到一個合適的起點,重播必要的步驟直到抵達中斷點。這樣做的好處是可以保證一致性,但也意味著任何「非確定性」或「具副作用」的操作都必須被妥善處理,否則在重播時會出現不同的結果,甚至重複執行危險的動作。
為了讓工作流在恢復時能保持一致,需要遵循幾個設計準則:
這些原則讓持久化不只是「把狀態存起來」,而是能真正做到斷點續傳 + 一致重播。即使 Agent 被迫中斷,再次恢復時仍能沿著相同的歷程,產生相同的輸出。
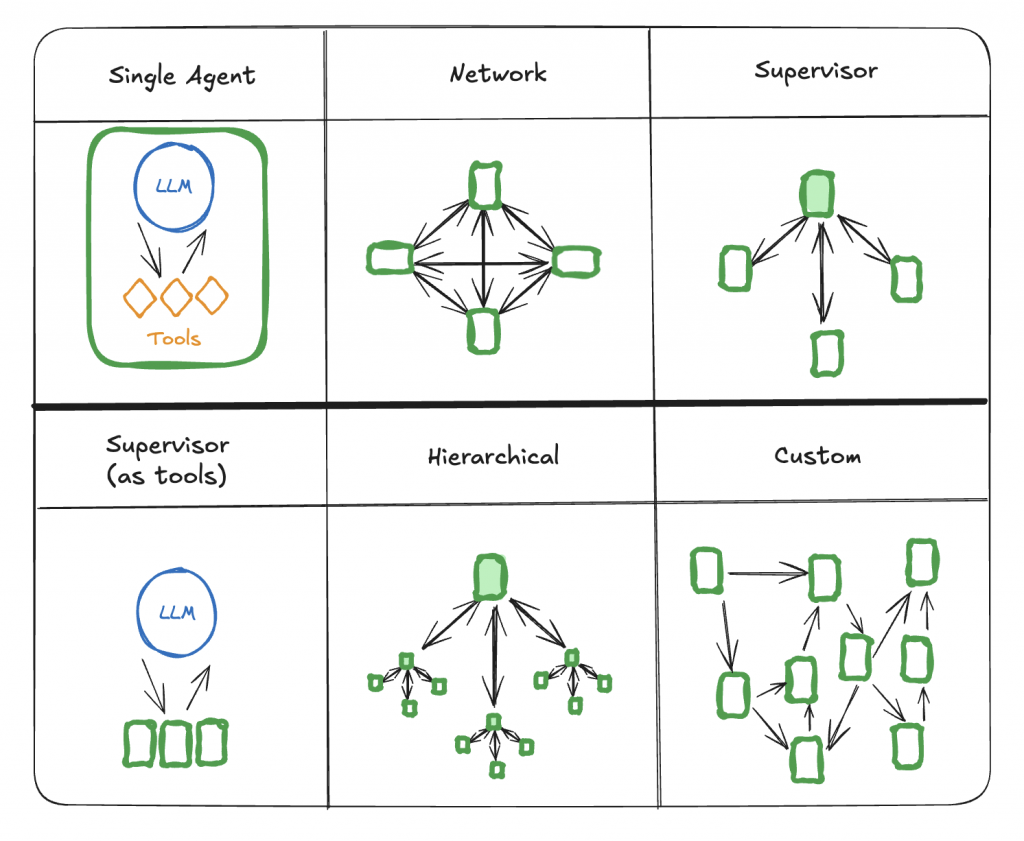
真實世界不是直線馬拉松,而是十字路口與環狀交流道的混成體:條件分支、錯誤旁路、並行處理、人工審批與等待外部事件……若仍用一條線性的 ReAct 迴圈硬扛,系統會越補越碎。你需要的是把「思考與行動」升級為可視、可維護的決策網路。
框架價值
interrupt/Command),例如刪庫前必須人審、發信前必須確認樣稿,降低風險、增加可追溯性。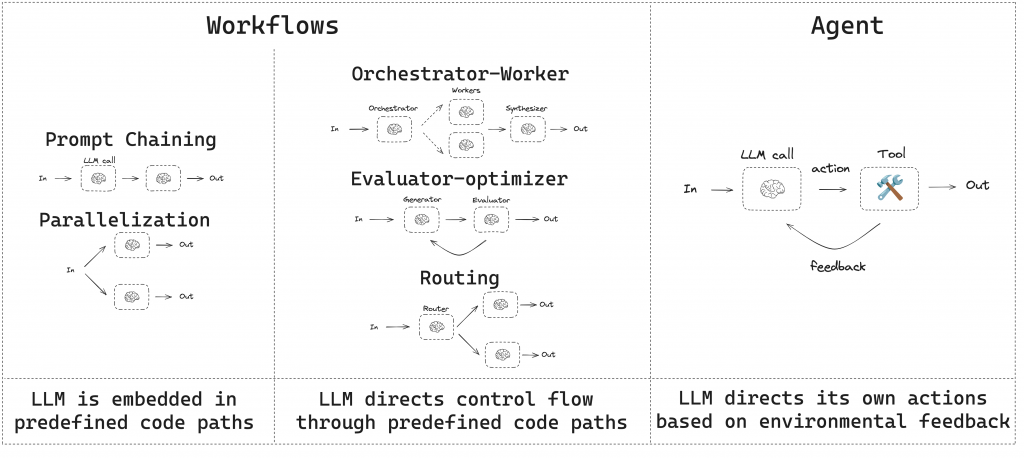
這圖是 LangChain 團隊對「工作流(Workflows)」和「代理(Agents)」的區分。他們認為 LLM 在系統中的角色有不同層次:
簡單來說,Workflow 比較像「照劇本走」,而 Agent 更像「自己導戲」,這也是 LangChain 為什麼同時提供工作流設計與 Agent 框架,讓開發者依場景選擇合適的模式。
透過前面的探討,我們已經看見了從簡單的 ReAct 迴圈到完整 Agent framework 的差距,也理解了記憶、持久性與工作流等核心支柱,如何一步步支撐起產品級的 LLM 應用。這些概念讓我們對 Agent 的運作方式有了更深一層的認識,不再只是「跑得動的程式碼」,而是「能承受真實世界挑戰的系統」。
然而,這其實只是起點。真實的應用場景中還會遇到更多挑戰:安全與隱私、成本控制、可觀測性、評估與迭代方法論……每一個都足以決定一個 Agent 能不能走出實驗室、走進真實商業環境。
就讓我們繼續再接下來的日子中繼續往下深挖,探討 LLM Agent 應用的奧秘吧!
References:


 iThome鐵人賽
iThome鐵人賽